

How to extract data from Adobe Campaign
Data analysts usually have their own analytics platforms where they sculpt raw data from various systems to create insights and nice charts for the management or quartely meetings. One way to extract data from the platform with little to no code is to use data extraction (file).
What data are usually extracted?
The most extracted data are logs from various marketing activities, consent changes, captured leads, survey results or any changes to recipient data done either by themselves or another system that could be integrated with platform. Marketing activities create logs and mostly revolve around folowing tables:
- Deliveries
nms:delivery– Deliveries that go out from the platform for any channel you have enabled. - Broad log
nms:broadLogRcp– contains information on what communication is sent to a particular recipient and whether it was successfully delivered or not. - Recipient tracking log
nms:trackingLogRcp– engagement events, such as clicks or opens, captured from communication. - Recipient exclusion log
nms:excludeLogRcp– Contains information about all excluded recipients and the reason from particular communication. - Quarantine
nms:address– Contains all quarantined recipients coming from hard bounces, soft bounces, manual input, any legacy suppression import, or users who marked communication as spam. Such records come back in the form of feedback loops and are automatically marked by Adobe Campaign as blacklisted.
How to extract data
How do we set up extract in a technical workflow? Simply prepare any data in your workflow that you want to export, either directly or through various transformations, such as joining data from another table or performing aggregate operations to get cumulative results. You can export data that is also saved in lists, created by one or multiple technical processes and collected throughout a certain time span (weekly, monthly).
Set up the data extract activity
At this point we have data in our workflow and we are ready to extract them.
Drag and drop the Data Extract (file) activity into the workflow. Now it’s time to set it up. Firstly, after we open the activity, we have to name the file that will be extracted. To add custom parameters from instance variables or the actual date, you can use JavaScript tags.

The next step is to edit the file format.
Following the wizard steps, where we can add columns to the export, transform values using the expression builder (using aggregate functions if needed, string function, concatenate values and create new columns or map values), and where the expression builder is lacking, we can modify values with JavaScript.
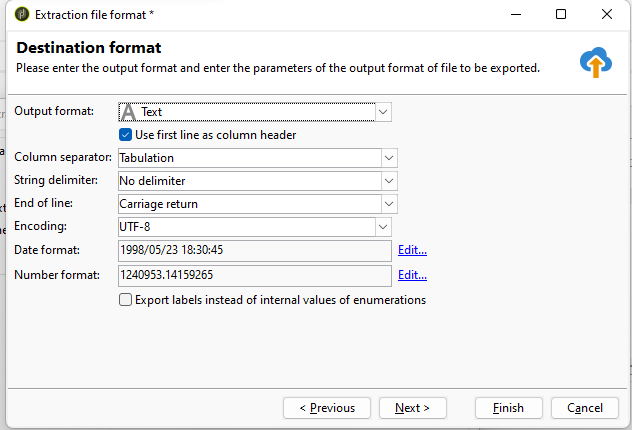
We will set up also the destination format. Following is my usual settings I use for almost all of my extracts.
Output format: text – yes there is also CSV but hear me out. When we set up the CSV we cannot change the End of line character setting. This has to be amended depending on the target system OS. Windows typically uses CRLF (Carriage Return + Line Feed) as the newline sequence. Linux and Unix-based systems typically use LF (Line Feed) alone as the newline sequence and MacintoshCR(Carriage Return) line break types. This setting if set wrongly can cause that file won’t be imported.Encoding: UTF-8 is a requirement when working with latin character sets.String delimeter: When extracting free text, it’s possible to encounter a column separator within the text, causing issues during import. To address this, use a different column separator or add string delimiters, typically double quotes (“).
On the last step of the wizard, where we can add additional data formatting functions such as simple transformations like upper case, lower case, or smart case. I often use this when exporting enumerations to map their numeric values to their text representation. To add a computed field, we click on the new button on the right side.
I have just recently found that you can also automatically let adobe campaign export labels of enumerations when checking the option “Export labels instead of internal values of enumerations”
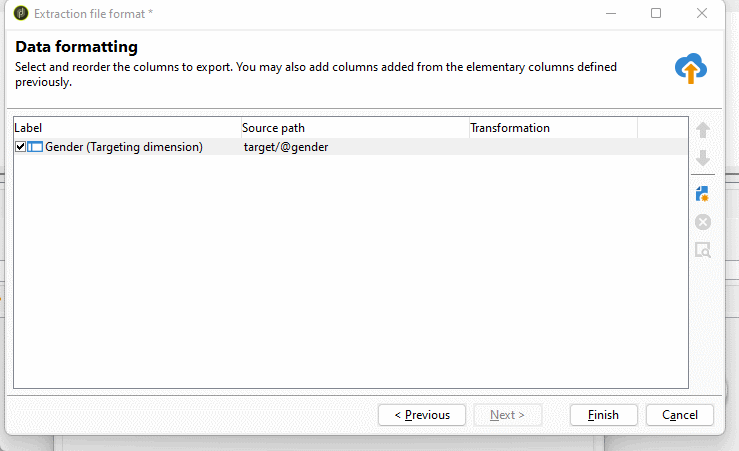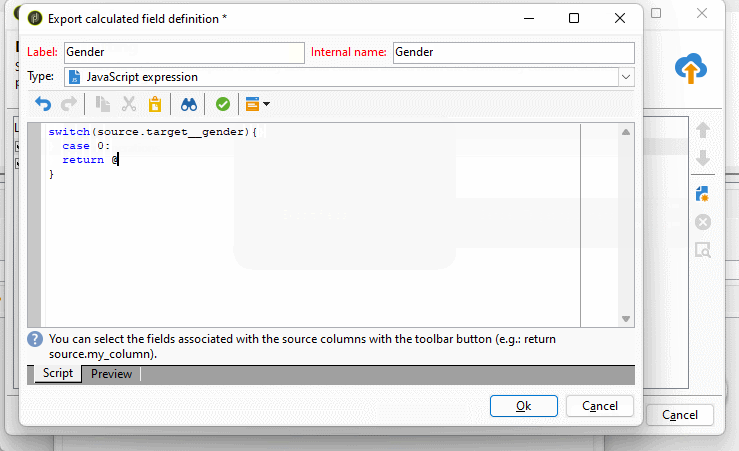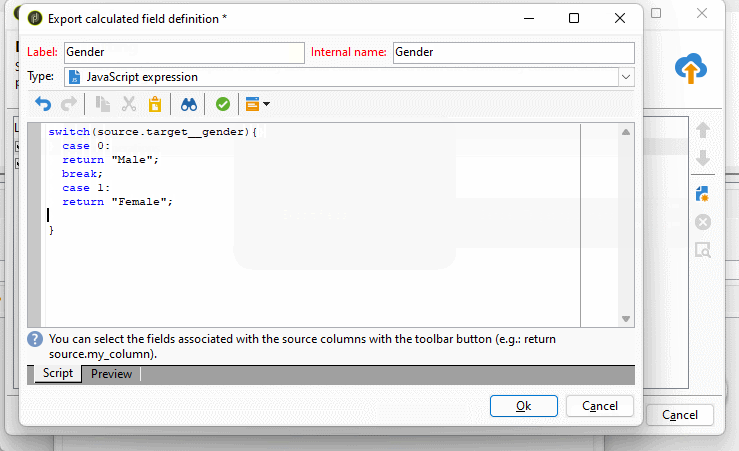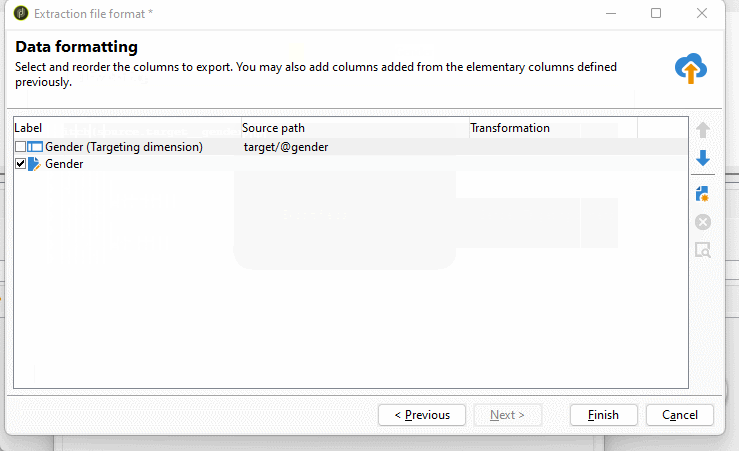
Also as well as with delivery activity we have object modification script tab where we can set additional settings or zip the extracted file if needed. To read more about the file extract activity visit the official doucmentation or if case of any doupts visit experience league forum.
Share With Others













